Przekształcenia morfologiczne, kontekstowe i rozmyte
Post ten jest pierwszym z trzech w cyklu związanym z tematem badania wpływu wstępnej filtracji obrazu na wyniki segmentacji wododziałowej. Temat ten powinien zainteresować wszystkie osoby rozpoczynające swoją przygodę z grafiką komputerową i analizą obrazu.
W pierwszej części postaram się przybliżyć pojęcia związane z podstawowymi przekształceniami jakie można wykonać na obrazie. W drugiej części omówiona zostanie segmentacja wododziałowa. Kolejny wpis będzie dotyczył narzędzia jakie napisałem w celu przeprowadzania badań wpływu wstępnych przekształceń na wyniki segmentacji wododziałową. Tematem ostatniego wpisu w tym cyklu będą natomiast same wyniki, które udało się uzyskać podczas badania obrazów RTG szczęki człowieka.
Zacznijmy od teorii.
Przekształcenia obrazu
Przekształcenia punktowe
Wyrównanie histogramu jest to przykład przekształcenia punktowego obrazu w wyniku którego otrzymuje się obraz, w którym wszystkie poziomy szarości są równomiernie wykorzystane. Wyjściowy obraz charakteryzuje się lepszym kontrastem. Jeśli prawdopodobieństwo wystąpienia poziomu szarości wynosi:
\[p(r_k)=\frac{n_k}{n}\]gdzie: \(r_k\) – poziom szarości k, \(n_k\) – liczba pikseli w obrazie wejściowym, których wartość wynosi \(r_k\), \(n\) – liczba wszystkich pikseli w obrazie, to wzór na wyrównanie histogramu przedstawia się następująco:
\[s_k = \sum_{0<j<k}p(r_j) = \sum_{0<j<k}\frac{n_j}{n}\]gdzie: \(s_k\) – poziom szarości w obrazie wyjściowym, \(k = 0,\ldots,L-1\), L – liczba odcieni szarości w obrazie wejściowym[1].
Przekształcenia morfologiczne
Przekształcenia morfologiczne polegają na wykonywaniu podstawowych przekształceń zbiorów, takich jak suma, różnica, dopełnienie i translacja, na elementach zbioru jakim jest obraz - na pikselach. W przekształceniach morfologicznych często stosuje się element strukturujący - niewielki, specjalnie przygotowany zbiór wartości będący argumentem funkcji przekształcenia morfologicznego [2,1].
Translacja
Translacja zbioru \(A\) przez wektor \(b\) oznacza że każdy element zbioru \(A\) jest przesunięty w swojej dziedzinie zgodnie ze wzorem [2,1]:
\[A+b = \{(a+h)|a \in A\}\]Erozja
Erozja obrazu \(A\) elementem strukturującym \(B\) oznacza iloczyn translacji \(A\) poszczególnymi elementami zbioru \(B\) [2,1]:
\[E(A,B) = \bigcap_{b \in B}(A-b)\]Dylacja
Dylacja obrazu \(A\) elementem strukturującym \(B\) oznacza sumę translacji \(A\) poszczególnymi elementami zbioru \(B\)[2,1]:
\[D(A,B) = \bigcup_{b \in B}(A+b)\]Otwarcie
Otwarcie obrazu \(A\) elementem strukturującym \(B\) jest złożeniem erozji oraz dylacji[2,1]:
\[O(A,B) = D(E(A,B),B)\]Zamknięcie
Zamknięcie obrazu \(A\) elementem strukturującym \(B\) jest złożeniem dylacji oraz erozji[2,1]:
\[C(A,B) = E(D(A,B),B)\]White Top Hat
Transformata White Top Hat oznacza różnicę obrazu wejściowego \(A\) i jego otwarcia elementem strukturującym \(B\)[2,1]:
\[WTH(A,B) = A-O(A,B)\]Black Top Hat
Transformata Black Top Hat oznacza różnicę zamknięcia obrazu \(A\) elementem strukturującym \(B\) i obrazu wejściowego \(A\) [2,1]:
\[BTH(A,B) = C(A,B)-A\]Gradient morfologiczny
Gradient morfologiczny oznacza różnicę pomiędzy dylacją obrazu \(A\) elementem strukturującym \(B\) a erozją tego samego obrazu tym samym elementem strukturującym[2,1]:
\[G(A,B) = D(A,B)-E(A,B)\]Przekształcenia kontekstowe
Filtr medianowy
Przekształcenie nazywane filtrem medianowym polega na przypisaniu pikselowi znajdującemu się pośrodku okna wartości będącej medianą wartości pikseli znajdujących się w danym oknie. Filtry medianowe pozwalają na usunięcie z obrazów szumów, zwłaszcza szumów typu “pieprz i sól”, przy czym nie wpływają znacząco na kontury obiektów znajdujących się na obrazie. Okna stosowane w filtrach medianowych mają kształt kwadratów o środku znajdującym się na współrzędnych aktualnie rozpatrywanego piksela[1].
Przekształcenia wykorzystujące elementy logiki rozmytej
Zbiory rozmyte
Logika rozmyta jest produktem teorii zbiorów rozmytych. W teorii zbiorów rozmytych, w przeciwieństwie do klasycznej teorii zbiorów, przynależność elementu do zbioru nie jest opisana przy pomocy zbioru dwóch wartości {0, 1}, lecz jako wartość z przedziału [0, 1]. Dzięki temu możliwe jest takie przedstawianie podzbiorów wszystkich możliwych wartości rozpatrywanych zbiorów na jakie wskazywałaby baza zebranej wiedzy. Wartości z przedziału [0, 1], przypisywane poszczególnym elementom zbiorów rozmytych noszą nazwę stopni przynależności danego elementu do zbioru[3].
Zmienne lingwistyczne
W teorii zbiorów rozmytych występują zbiory określane poprzez zmienne lingwistyczne:
Przez zmienną lingwistyczną rozumiemy zmienną, której wartościami są słowa lub zdania w języku naturalnym lub sztucznym. Dla przykładu Wiek jest zmienną lingwistyczną, jeśli jej wartości są wyrażone słowami, a nie liczbami, to znaczy młody, niemłody, bardzo młody, całkiem młody, stary, nie bardzo stary, nie bardzo młody itd. zamiast 20, 21, 22, 23, …[3]

Dzięki zastosowaniu zmiennych lingwistycznych o wiele łatwiejsze stało się takie opisywanie badanych wielkości, by utworzone przedziały odzwierciedlały wiedzę ekspertów w danej dziedzinie. Zastosowanie zbiorów rozmytych, połączone z tworzeniem bazy wiedzy eksperckiej, pozwoliło na o wiele łatwiejsze, a dzięki temu szybsze, rozwiązanie wielu problemów z dziedziny automatyki i elektroniki. Algorytmy wykorzystujące zbiory rozmyte wykorzystywane są w sterowaniu procesami wytwórczymi, sterowaniu powszechnie używanymi urządzeniami elektronicznymi oraz w innych dziedzinach. Algorytmy te zostały wykorzystane w wielu dziedzinach informatyki, w tym także w grafice komputerowej. W przypadku obrazu, rozpatrywanym zagadnieniem może być np. podobieństwo pikseli, a utworzonymi zmiennymi lingwistycznymi oceny jakie można temu podobieństwu przypisać, np. bardzo małe, małe, średnie, duże, bardzo duże. Przykład takich zbiorów rozmytych, przedstawiony w formie wykresy pokazano na rysunku 1. Widać na nim, że zbiory nie są ostre, istnieją takie wartości różnicy intensywności pikseli, dla których przynależność do danego zbioru zawiera się w przedziale [0, 1]. Co więcej istnieją takie wartości różnicy intensywności pikseli, dla których wartość ta zawiera się w dwóch (w tym przypadku), ogólnie w więcej niż jednym zbiorze. Odzwierciedla to sytuację, w której ekspert dziedziny nie może jednoznacznie wskazać do jakiego zbiory przyporządkować zadany element [3].
Reguły decyzyjne
Do opisu związków pomiędzy zbiorami wprowadzono wyrażenia warunkowe w postaci:
\[jeżeli \langle\ poprzednik\_reguly\ \rangle\ to \langle\ nastepnik\_reguly\ \rangle\]Każde takie wyrażenie nazywane jest regułą decyzyjną, lub w skrócie regułą[3].
Filtr redukujący szum wykorzystujący elementy logiki rozmytej
W artykule [4] zaproponowano algorytm służący do redukcji szumu na obrazach, wykorzystujący technikę rozmytą. Działanie algorytmu dzieli się na dwie części. Podczas pierwszej z nich, dla każdego piksela obrazu określane jest czy jest on pikselem będącym szumem i w jakim stopniu można to określić, etap ten nazwano Fuzzy Noise Estimation. Określenie czy piksel zawiera szum następuje po obliczeniu dwóch parametrów rozmytych. Pierwszy z nich to różnica w intensywności koloru pomiędzy danym pikselem a pikselami w jego 8-sąsiedztwie, dalej oznaczana jako deg:
\[dif = min|f(x, y)-f(x', y')|\]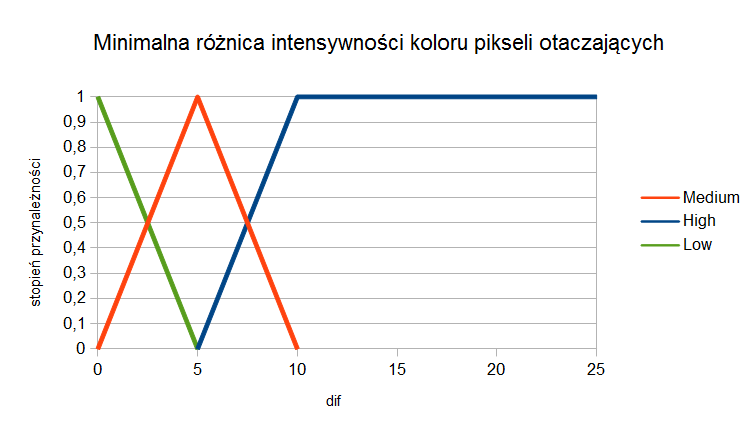
Pierwszy parametr może przyjmować następujące wartości lingwistyczne: Low, Medium, High. Wykres stopni przynależności pokazano na rysunku 2.
Drugi parametr to liczba pikseli podobnych do danego piksela w jego 8-sąsiedztwie, dalej oznaczany jako num. Podobieństwo określa się na podstawie różnicy intensywności koloru i progu, poniżej którego ta różnica oznacza podobieństwo, a powyżej którego niepodobieństwo dwóch pikseli:
\[num = \{ (x', y')|(x', y') \in N_8 (x, y) \& |f(x, y) - f (x', y')| < treshold \}\]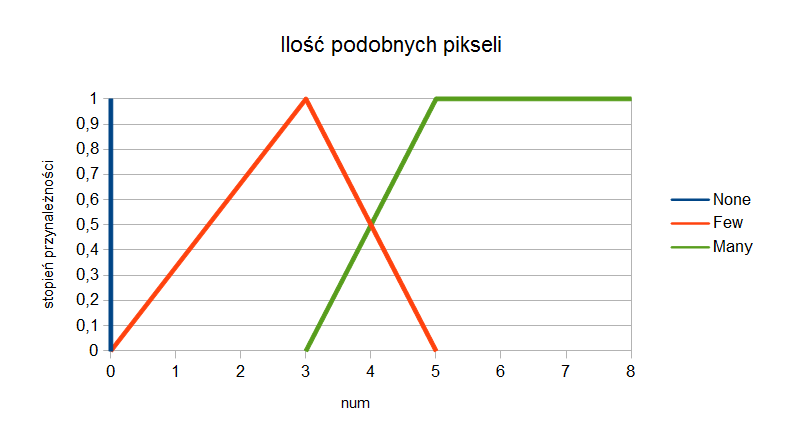
Drugi parametr może przyjmować następujące wartości lingwistyczne: None, Few, Many. Wykres stopni przynależności pokazano na rysunku 3.
Na podstawie przedstawionych wcześniej parametrów przygotowano następujące reguły decyzyjne, wyznaczające stopień w jakim dany piksel jest uznawany za piksel zaszumiony, danej oznaczany jako deg. Parametr ten może przyjmować wartości lingwistyczne takie jak Small, Moderate, Big, Very Big:
jeżeli (dif jest Low) i (num jest None) to (deg jest Moderate)
jeżeli (dif jest Low) i (num jest Few) to (deg jest Big)
jeżeli (dif jest Low) i (num jest Many) to (deg jest Very Big)
jeżeli (dif jest Medium) i (num jest None) to (deg jest Small)
jeżeli (dif jest Medium) i (num jest Few) to (deg jest Moderate)
jeżeli (dif jest Medium) i (num jest Many) to (deg jest Big)
jeżeli (dif jest High) i (num jest None) to (deg jest Small)
jeżeli (dif jest High) i (num jest Few) to (deg jest Moderate)
jeżeli (dif jest High) i (num jest Many) to (deg jest Moderate)
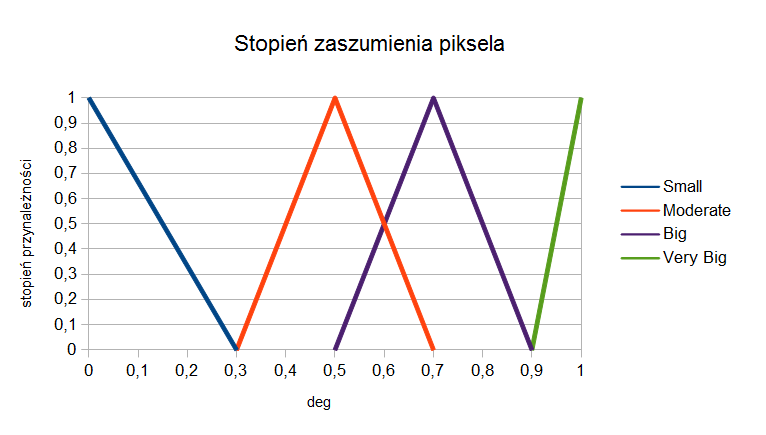
Wykres stopni przynależności pokazano na rysunku 4.
Parametr deg jest wyjściem algorytmu Fuzzy Noise Estimation, a jednocześnie jednym z argumentów wejściowych dla algorytmu Fuzzy Smoothing. W drugim algorytmie, aby wyliczyć wagi dla wszystkich pikseli znajdujących się w 8-sąsiedztwie obliczany jest parametr diff:
\[diff = |f(x,y) - f(x-k, y-l)|\]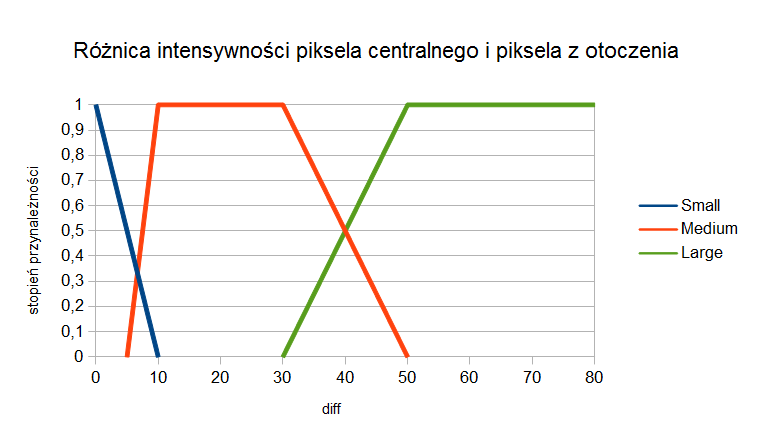
Wykres stopni przynależności pokazano na rysunku 5. Jeśli wynik działania jest duży to mała waga powinna zostać przypisana do danego piksela, by zredukować jego udział w procesie uśredniania.
Na podstawie otrzymanych wartości rozmytych diff oraz wyjścia poprzedniego algorytmu deg utworzono następujące reguły decyzyjne wyznaczające parametr weight będący zbiorem rozmytym w którym znajduje się szukana wartość wagi dla danego piksela:
jeżeli (diff jest Small) i (deg jest Low) to (weight jest Small)
jeżeli (diff jest Small) i (deg jest Moderate) to (weight jest Moderate)
jeżeli (diff jest Small) i (deg jest Big) to (weight jest Big)
jeżeli (diff jest Small) i (deg jest Very Big) to (weight jest Very Big)
jeżeli (diff jest Medium) i (deg jest Low) to (weight jest Small)
jeżeli (diff jest Medium) i (deg jest Moderate) to (weight jest Moderate)
jeżeli (diff jest Medium) i (deg jest Big) to (weight jest Big)
jeżeli (diff jest Medium) i (deg jest Very Big) to (weight jest Very Big)
jeżeli (diff jest Large) i (deg jest Low) to (weight jest Small)
jeżeli (diff jest Large) i (deg jest Moderate) to (weight jest Moderate)
jeżeli (diff jest Large) i (deg jest Big) to (weight jest Big)
jeżeli (diff jest Large) i (deg jest Very Big) to (weight jest Very Big)
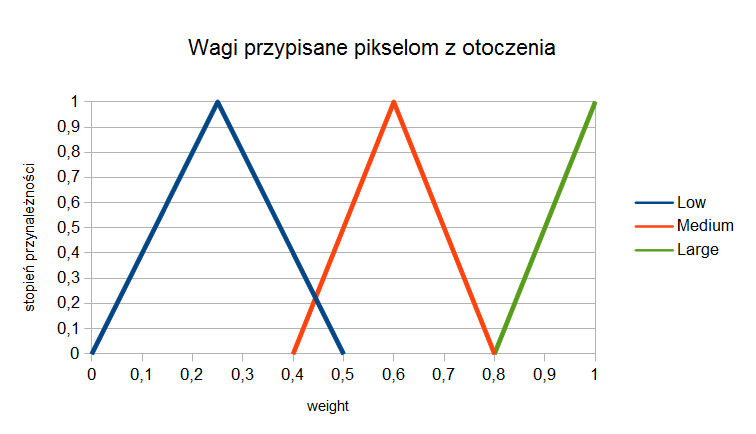
Wykres stopni przynależności pokazano na rysunku 6. Na podstawie otrzymanych w algorytmie Fuzzy Smoothing wartości dobiera się wagi dla pikseli znajdujących się w oknie 3x3 i oblicza nową wartość dla dla piksela centralnego.
Literatura
- A. Świtoński. Wykłady z przedmiotu Grafika Komputerowa i Rozpoznawanie Obrazów. Politechnika Śląska, 2013
- M. Nieniewski. Segmentacja obrazów cyfrowych. Metody segmentacji wododziałowej. Akademicka Oficyna Wydawnicza EXIT, 2005
- D. Driankov, H. Hellendoorm, M. Reinfrank. Wprowadzenie do sterowania rozmytego. Wydawnictwa Naukowo-Techniczne, 1993
- H. V. Nejad, H. R. Pourreza, H. Ebrahimi. A Novel Fuzzy Technique for Image Noise Reduction. World Academy Of Science, Engineering and Technology, 2008
Treść tego wpisu zawiera fragmenty mojej pracy dyplomowej “Badanie wpływu wstępnej filtracji na proces segmentacji w analizie patologicznych zmian w obrębie zębów widocznych na zdjęciach RTG”.
Zobacz także: